이번 장부터는 정보들이 어떻게 표현되고 어떻게 활용되는지 살펴볼 것이다. 이장에서 일단 code가 기계어로 어떻게 표현되는지 그리고 정수 data에 초점을 맞추고 사칙연상의 진행 과정 또한 살펴볼 예정이다.
처음으로 살펴볼 녀석은 Bit이다. 일단 Bit는 Binary Digit의 줄임말이다. Bit는 0과 1로 이루어져있고 비트 하나로는 0과1 두가지만 표현할 수 있겠지만 컴퓨터는 여러개의 비트를 사용하여 다양한 데이터 타입을 표현할 수 있다. 만약에 n 비트가 주어지면 총 2^n가지를 표현할 수 있다. 예를 들어서 2의 32승이면 대략 0 ~ 42억정도의 수가 표현 가능하다. 일반적으로 우리가 한 문자를 표현할때 8비트 다른 말로 1바이트로 표현하는데 그 이유는 2의 8승은 256개 문자를 표현 할 수 있고 256개 문자이면 영문 기준으로 모든 문자를 사용할 수 있다. 물론 한글이나 한문 같은 경우엔 더 큰 바이트가 필요로하다. 총괄적으로 말하자면 n이 정해지면 value의 range를 정할 수 있다라고 말할 수 있겠다.
Byte는 메모리상 가장 작은 addressable의 단위이다. 그 말은 Byte단위로 주소를 지정하게된다는 의미이기도 하다. Byte는 Binary Term의 약어이다. 기본적으로 1 Byte는 8bits로 구성되어 있고 문자 하나를 표현하는 단위이다.
주로 우린 16진수, Hexadecimal로 data를 표현한다. 그 이유는 2진수의 숫자들은 너무 길기 때문이다. 아래는 16진수 10진수 2진수를 표현한 표이다.

16진수에서 2진수 변환 그리고 2진수에서 16진수 변환은 굉장히 쉽다. 각 2진수 4자리는 하나의 16진수 숫자를 뜻한다.
그럼 1바이트는 00(16진수) ~ FF(16진수)으로 표현가능하다고 볼수 있겠다.
참고로 10진수에서 16진수, 2진수 변환은 우리가 고등학교에서 배웠던 그 지식으로 변환가능하다.
Bit, Byte이외에도 Word라는 용어도 있는데 word의 기본적인 두가지 특징은 첫번째 정수 데이터 또는 포인터를 표현하는 기본 단위이다. 두번째는 CPU 메모리 데이터를 전송하는 단위이다. 일반적으로 이 두가지는 같고 요즘 근래의 컴퓨터들은 32/64비트 컴퓨터를 사용하다 보니 word의 크기도 32/64비트이다. 고로 32비트는 4기가의 가상 주소 공간을 가지게 된다.
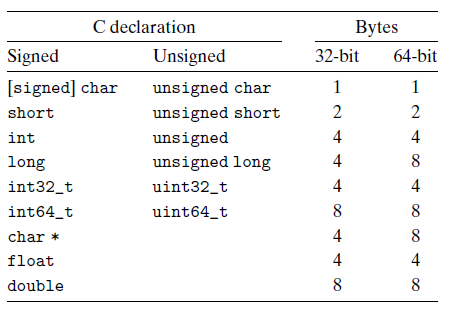
위 표를 보게 되면 32bit 64bit 머신이 다를 경우 변수의 크기가 달라지는 현상도 나타난다. 이곳에선 long과 char*일 경우엔 서로 표현할 수 있는 데이터의 범위가 다르다.
그 다음 설명을 할건 Byte Ordering이란 것이다. 먼저 밑의 그림 예를 살펴보겠다.
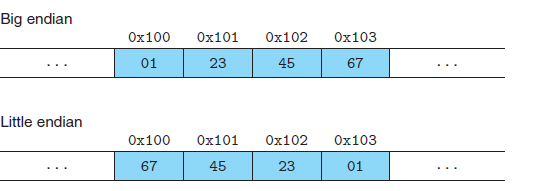
만약에 우리가 0x01234567이란 4바이트(왜 4바이트인지는 각 두 숫자가 8비트이기 때문에) 의 숫자를 0x100에 저장하라라고 했을 때 두가지의 저장 방법이 있다. 하나는 01 23 45 67 이렇게 순서대로 저장하는 방식인 Big endian방식이 있고 다른 하나는 거꾸로 저장을 하는 Little endian 방식이 있다. 우리가 주로 사용하는 Inter계열의 컴퓨터는 little endian방식을 사용한다. 이렇게 little endian을 주로 사용하는 이유는 4바이트 즉 32비트의 값을 저장할 때 거꾸로, 작은 값들을 먼저 저장하게 되면 사용하지 않는 비트들이 있을 수 있기 때문입니다. 예를 들자면 0x0000001의 값을 저장할 때 little endian을 사용하여 01을 먼저 저장하고 나머지 00들을 저장하게되면 계산을 할때 굳이 뒤의 00 값들을 살펴볼 필요가 없기 때문입니다.
Big endian은 주로 IBM 큰컴퓨터 혹은 SUV Microsystems기계들이 사용하고 있다.
이 두가외에도 Bi endian이라고 두가지 동시에 사용하는 방식도 있지만 결국 이것도 속을 들여다보면 Little endian을 사용하게 된다. ㅎ
그 다음으로 String이 어떻게 표현되는지 살펴보자. String은 NULL로 끝나는 문자들의 배열이다. 일반적으로 아스키코드(ASCII)로 표현되고 '0' ~ '9' 숫자를 표현하는 문자들은 0x30 ~ 0x39로 표현 가능하다. 'a'부터 'z'는 0x61 ~ 0x7A로 표현이 가능하다. 아스키코드외에도 사용하는 기준이 있는데 그건 IBM사의 앱시딕(EBCDIC)이라고 한다. ASCII코드는 원래 7비트였지만 나중에 8비트로 변경하였지만 앱시딕은 원래부터 8비트였다고 한다.
여기서 코드에 대해서 잠깐 살펴보고 가자 밑에 있는 표현을 가볍게 살펴보도록 하자


int sum 코드를 기계어로 밑에다가 표현을 하였다. 각 운영체제마다 같은 코드를 컴파일하였지만 서로 다른 기계어코드가 나타났다. 이렇듯 서로 다른 머신 타입은 기본적으로 명령어를 encoding하는 방법도 다르다. 그리고 위에서 살펴봤듯이 OS만 달라도 Binary Code의 표현이 달라질수도 있다. 이에 대한 구체적인 설명은 3장에서 곧 만날수 있을 것이다.
그 다음의 내용은 굉장히 쉬워서 아주 간단하게만 살펴보고 빠르게 넘어가도록 하겠다.
Boolean algebra는 ~,&,|,^가 존재한다.
C에서 Logical Operation은 !, &&, || 각 부호가 어떤 것을 의미하는 지는 굳이 설명하지 않겠다.
Shift Operation은 3가지가 존재한다. 그냥 <<가 있고 logical >> 그리고 Arithmetic >>가 존재한다.
logical은 어떤 수가 스킵되어도 무조건 추가로 0이 들어오는 반면에 Arithmetic은 밀려 없어지는 비트가 0이냐 1인가에 따라서 들어오는 수가 1이될수도 0이 될수도 있다. 이것만 기억하도록 하자.
나머지 내용은 다음 게시물에서....
'시스템프로그램' 카테고리의 다른 글
| [시스템프로그램]02-2-1 정수의 사칙연산(1) (0) | 2020.04.27 |
|---|---|
| [시스템프로그램]02-1-3 정보의 표현과 활용(3) (2) | 2020.04.26 |
| [시스템프로그램]02-1-2 정보의 표현과 활용(2) (2) | 2020.04.20 |
| [시스템프로그램]01-2 컴퓨터 시스템의 투어 (0) | 2020.04.17 |
| [시스템프로그램] 01-1 컴퓨터 시스템의 투어 (2) | 2020.04.17 |




댓글